오랜만에 친구가 cpp 공부를 하고있다 하여 미로만들기를 추천하며 나역시 미로를 만들어 보았다

위 영상은 이번에 제작물이다 {
1. 맵 램덤생성
2.방향키 입력시 플레이어 움직임
3.플레이어의 시야 제한
}
우선 맵 헤더 파일이다.
class Mazemap
{
public:
enum PlayerMoverDirection
{
UP,
DOWN,
LEFT,
RIGHT,
MovendPointeEndPoint
};
enum MapState {
road = 0,
wall,
startPoint,
EndPoint
};
const char MapStateChar[4][4] = { "□","■","○","☆" };
int MapSizeLW = 25;
int PlayerEyesight = 5;
int PlayerPos[2] = { 0,0 };
std::vector<std::vector<int>> Map{};
void init();
void PlayerMove(PlayerMoverDirection m);
void MapRestart();
private:
// 맵생성 완료 확인
bool IsGenerateMap = false;
/// <summary>
/// [4][2] [1]상 [2]하 [3]좌 [4]우
/// </summary>
const int MoverDirection[4][2] = { {1,0} ,{-1,0} ,{0,-1} ,{0,1} };
//start point end point 의 거리차이
const int Sp_Ep_MDistance = 3;
//랜덤 관련 클래스
uniform_int_distribution<int> RandomMapPoint;
random_device rd;
mt19937_64 mt;
void AutomaticMapMaker(int MapSize);
void ProceduralGeneration(int generatex, int generatey, PlayerMoverDirection goback = PlayerMoverDirection::MovendPointeEndPoint);
std::vector<PlayerMoverDirection> canDoitGeneration(int x, int y, PlayerMoverDirection goback);
};
맵 클레스엔 맵과 플레이어의 이동을 표현할 변수들을 만들어준다.
우선 맵 생성을 만들었는데.
맵 램덤 생성에서 어떤식으로 생성할지 생각하다 가장 기본적인 생각은 DFS 였고
플레이어 위치에서 시작을한뒤
{
왔던길을 제외한 갈수있는길을 탐색한다.
갈수 있는길은 특정 방향으로 2칸이 벽 일경우 가능
상하좌우 전부 길이없을경우 도착지점 배열에 추가한다.(막다른 길을 도착지점으로 하기위함)
갈수 있는길의 방향을 배열로 받은뒤 섞어준다.
배열의 순서대로 다음 방향으로 2칸이동후 사이의 1칸도 길로 채워준다.
}
맵 초기화 시켜주기
맵을 생성후 start point를 지정해준다.
void Mazemap::MapRestart()
{
Map.clear();
AutomaticMapMaker(MapSizeLW);
}
void Mazemap::AutomaticMapMaker(int MapSize)
{
uniform_int_distribution<int> Maprange(0, MapSize-1);
int P_x, P_y, EndP_x, EndP_y = 0;
if (SpareEndPoint.size() > 0) SpareEndPoint.clear();
P_x = Maprange(mt);
P_y = Maprange(mt);
PlayerPos[0] = P_x;
PlayerPos[1] = P_y;
for (int i = 0; i < MapSize; i++) {
Map.push_back(std::vector<int>());
for (int j = 0; j < MapSize; j++) {
Map[i].push_back(1);
}
}
Map[P_x][P_y] = MapState::startPoint;
//Map[EndP_x][EndP_y] =MapState::EndPoint;
ProceduralGeneration(P_x, P_y);
int randPoint = Maprange(mt) % (SpareEndPoint.size() - 1);
Map[SpareEndPoint[randPoint][0]][SpareEndPoint[randPoint][1]] = MapState::EndPoint;
IsGenerateMap = true;
}
맵생성 코드의 기본적인 아이디어는
1.가는 방향으로 길을 채워준다.
2. 갈수 있는길을 탐색한다
3. 왔던길을 제외한다(받은 갈수있는길 배열에서).
4.만약 갈길이 있다면 queue 길찾기 배열에 추가한다.
5. 받은 방향 배열을 섞어준다
6.재귀함수로 현재위치와 queue의 일전에 추가한 다음방향으로 이동한다.
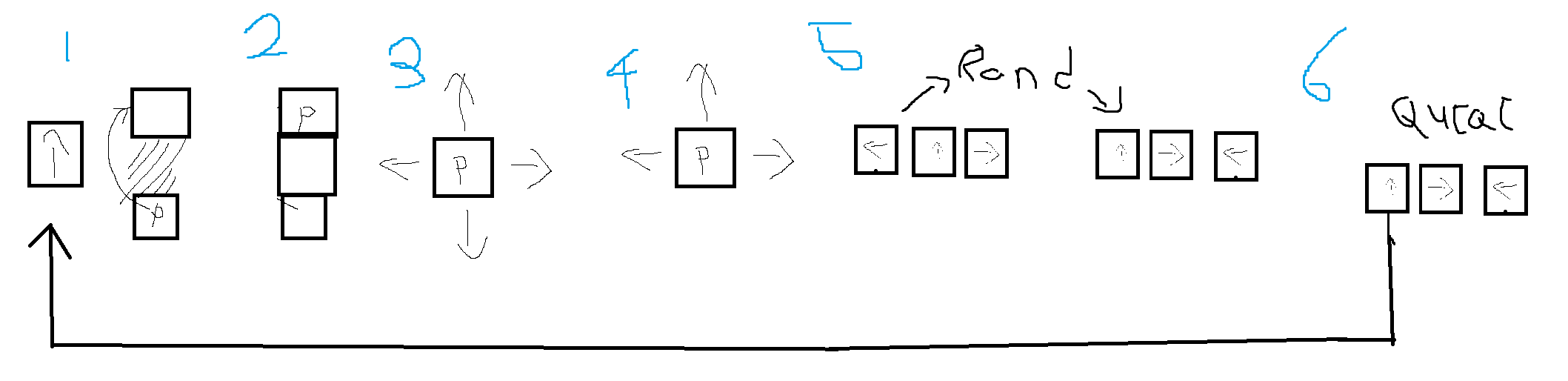
맵 생성 코드
void Mazemap::ProceduralGeneration(int generatex, int generatey, PlayerMoverDirection goback)
{
//길로 바꿔주기
if (Map[generatex][generatey] == MapState::wall){
Map[generatex - (MoverDirection[goback][0])][generatey - MoverDirection[goback][1]] = MapState::road;
Map[generatex][generatey] = MapState::road;
}
else if (Map[generatex][generatey] == MapState::road)
{
return;
}
////갈수있는 방향 받기
////같던길 제외 해주기
auto nextRoad = canDoitGeneration(generatex, generatey, goback);
////섞기
for (int i = 0; i < nextRoad.size(); i++) {
int a = RandomMapPoint(mt) % nextRoad.size();
if (a == i)continue;
PlayerMoverDirection m = nextRoad[i];
nextRoad[i] = nextRoad[a];
nextRoad[a] = m;
}
if (!(nextRoad.size() > 0)) {
SpareEndPoint.push_back({ generatex, generatey });
}
for (int i = 0; i < nextRoad.size(); i++) {
ProceduralGeneration(generatex + MoverDirection[nextRoad[i]][0] * 2, generatey + MoverDirection[nextRoad[i]][1] * 2, nextRoad[i]);
}
}
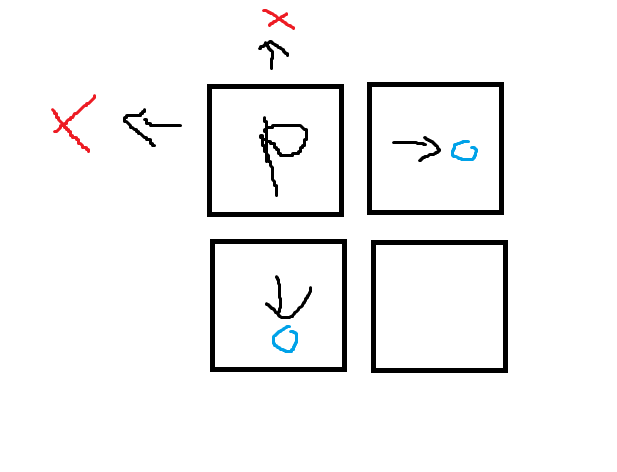
canDoitGeneration 함수 (갈수있는길을 탐색한뒤 [상하좌우] enum 배열을 반환한다)
std::vector<Mazemap::PlayerMoverDirection> Mazemap::canDoitGeneration(int x, int y, PlayerMoverDirection goback)
{
std::vector<PlayerMoverDirection> v;
if (x + 2 < MapSizeLW && Map[x + 2][y] == Mazemap::MapState::wall &&
Map[x + 1][y] == Mazemap::MapState::wall &&
goback != DOWN)v.push_back(UP);
if (x - 2 >= 0 && Map[x - 2][y] == Mazemap::MapState::wall &&
Map[x - 1][y] == Mazemap::MapState::wall &&
goback != UP)v.push_back(DOWN);
if (y + 2 < MapSizeLW && Map[x][y + 2] == Mazemap::MapState::wall &&
Map[x][y +1] == Mazemap::MapState::wall &&
goback != LEFT)v.push_back(RIGHT);
if (y - 2 >= 0 && Map[x][y - 2] == Mazemap::MapState::wall &&
Map[x][y - 1] == Mazemap::MapState::wall &&
goback != RIGHT)v.push_back(LEFT);
return v;
}
이후 움직이는 코드를 만들어준다
맵을 탈출하지 못하게 배열의 크길 방향 제한을 걸어준다.
std::vector<Mazemap::PlayerMoverDirection> Mazemap::canDoitGeneration(int x, int y, PlayerMoverDirection goback)
{
std::vector<PlayerMoverDirection> v;
if (x + 2 < MapSizeLW && Map[x + 2][y] == Mazemap::MapState::wall &&
Map[x + 1][y] == Mazemap::MapState::wall &&
goback != DOWN)v.push_back(UP);
if (x - 2 >= 0 && Map[x - 2][y] == Mazemap::MapState::wall &&
Map[x - 1][y] == Mazemap::MapState::wall &&
goback != UP)v.push_back(DOWN);
if (y + 2 < MapSizeLW && Map[x][y + 2] == Mazemap::MapState::wall &&
Map[x][y +1] == Mazemap::MapState::wall &&
goback != LEFT)v.push_back(RIGHT);
if (y - 2 >= 0 && Map[x][y - 2] == Mazemap::MapState::wall &&
Map[x][y - 1] == Mazemap::MapState::wall &&
goback != RIGHT)v.push_back(LEFT);
return v;
}그리고 main에서 움직이는 코드를 사용해서 이동한다.
void MazeMain::Update()
{
int keyInput;
keyInput = _getch();
if (keyInput == 224) {
keyInput = _getch();
}
if (keyInput == 115 || keyInput == 80) {
map.PlayerMove(Mazemap::PlayerMoverDirection::UP);
}
if (keyInput == 97 || keyInput == 75) {
map.PlayerMove(Mazemap::PlayerMoverDirection::LEFT);
}
if (keyInput == 100 || keyInput == 77) {
map.PlayerMove(Mazemap::PlayerMoverDirection::RIGHT);
}
if (keyInput == 119 || keyInput == 72) {
map.PlayerMove(Mazemap::PlayerMoverDirection::DOWN);
}
if (keyInput == 'r' || keyInput == 'R') {
map.MapRestart();
}
}
이제 메인에서 각종 코드들을 실행시킨다.
랜더는 더블버퍼 win api 코드를 들고와서 작성했다.
main
class MazeMain
{
public:
Mazemap map;
GameBoard GameRender;
void init();
void a_main();
string Render();
void Update();
~MazeMain();
bool Game = true;
private:
};
int main() {
MazeMain m;
m.init();
m.a_main();
}
void MazeMain::init()
{
map.init();
GameRender.Map_size = map.MapSizeLW;
GameRender.ScreenInit();
GameRender.func = [this]() {
return Render();
};
}
void MazeMain::a_main()
{
while (Game)
{
while (_kbhit() == 0) {
GameRender.Render();
Update();
}
}
}
그런다음
원하는 시야거리를 잡아준뒤 그이상을 넘어갈경우 맵을 벽과 같은 문자로 넣어버린다.
string MazeMain::Render()
{
string s;
//map.PlayerPos[0] map.PlayerPos[1]
for (int i = 0; i < map.Map.size(); i++)
{
for (int j = 0; j < map.Map[i].size(); j++)
{
if (map.PlayerPos[0] == i && map.PlayerPos[1] == j) {
s += map.MapStateChar[2];
continue;
}
if (
map.PlayerPos[0] + map.PlayerEyesight > i &&
map.PlayerPos[0] - map.PlayerEyesight < i &&
map.PlayerPos[1] + map.PlayerEyesight > j &&
map.PlayerPos[1] - map.PlayerEyesight < j
) {
s += map.MapStateChar[map.Map[i][j]];
}
else {
s += map.MapStateChar[Mazemap::MapState::wall];
}
s += map.MapStateChar[map.Map[i][j]];
}
s += "\n";
}
return s;
}'언어 > C++' 카테고리의 다른 글
| cpp 전처리기 (0) | 2023.09.05 |
|---|---|
| c++ std::function 사용하기 (0) | 2023.01.10 |
| 함수 포인터! (Function Pointer)! (0) | 2021.07.13 |
| 인라인 함수(Inline Function) (0) | 2021.06.15 |
| 네임스페이스 (9) | 2021.05.18 |