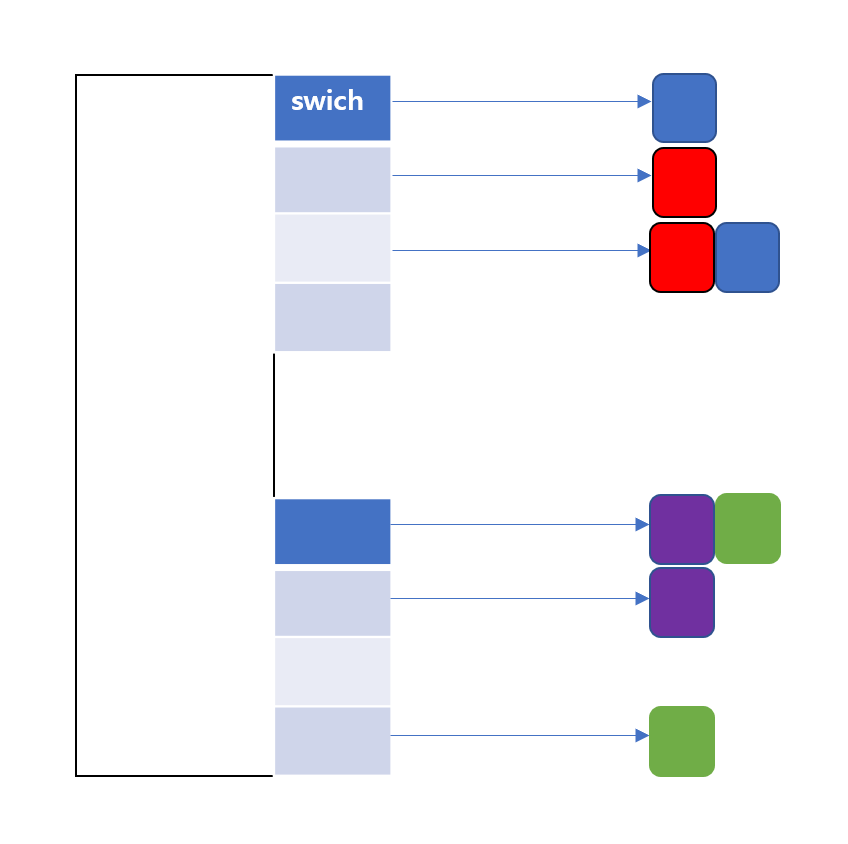
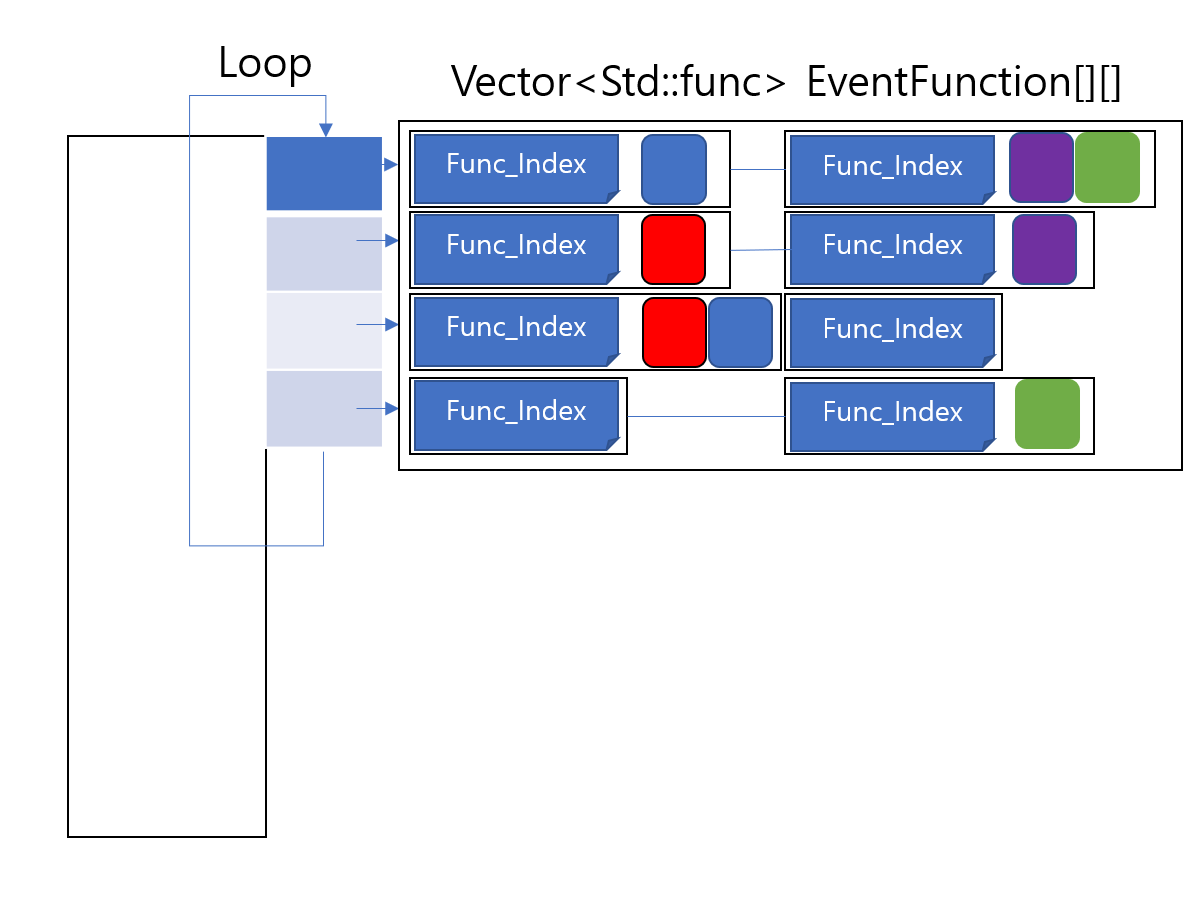
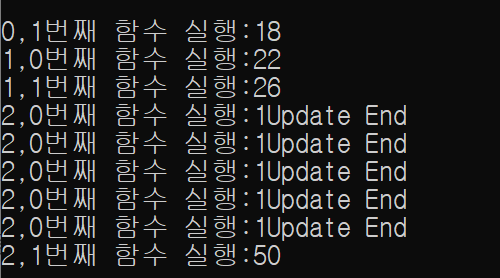
하지만 null 이 필요할수 있기때문에 자료형 뒤에 ? 를 붙이면 null 표현이 가능해진다.
사용 방식
값 타입 자료형 ? 변수명
int? a = 10;
int? b = null;
// int c = null; null을 허용하지 않는 값 형식classA{}
// A a?; null 을 허용하지 않는 값 형식 이여야 한다.int?[] arr = newint?[10];
//배열 선언방법
Nullable 값 형식에서 기본 형식으로 변환
int? a = 10;
int b = 0;
b = a ?? -1;
// a가 null 이면 -1이 들어가고 null이 아닐경우 a값이 그대로 들어가 10이 들어간다.
?? 연산자는 왼쪽 값이 null 이면 오른쪽 값을 사용하고 null이 아닐경우 왼쪽 값을 사용하는
일종의 null 을 검사하는 연산자다.
is
is 연산자로는 Nullable 형식인지 아닌지 구분 불가하다
마소 예제코드
int? a = 1;
int b = 2;
if ( a isint )
{
Console.WriteLine(int? instance is compatible withint);
}
if (b isint?)
{
Console.WriteLine("int instance is compatible with int?");
}
// Output:// int? instance is compatible with int// int instance is compatible with int?
GetType
Object.GetType은 Null 허용값 형식의 boxing으로 기본형식 값의 boxing과 동일하게 나온다.
GetType은 기본형식 Type 인스턴스를 반환한다.
int? a = 17;
Type typeOfA = a.GetType();
Console.WriteLine(typeOfA.FullName);
// Output:// System.Int32
그럼으로 아래 코드 처럼 구분할수 있다
마소코드
Console.WriteLine($"int? is {(IsNullable(typeof(int?)) ? "nullable" : "non nullable")} value type");
Console.WriteLine($"int is {(IsNullable(typeof(int)) ? "nullable" : "non-nullable")} value type");
boolIsNullable(Type type) => Nullable.GetUnderlyingType(type) != null;
// Output:// int? is nullable value type// int is non-nullable value type
//마소 c# 튜플 사용 사례var ys = new[] { -9, 0, 67, 100 };
var (minimum, maximum) = FindMinMax(ys);
// Output:// Limits of [-9 0 67 100] are -9 and 100
(int min, int max) FindMinMax(int[] input)
{
if (input isnull || input.Length == 0)
{
}
var min = int.MaxValue;
var max = int.MinValue;
foreach (var i in input)
{
if (i < min)
{
min = i;
}
if (i > max)
{
max = i;
}
}
return (min, max);
}
위 사용 사례에서 보이는것 처럼 minimum 과 maximum 을 따로 구하지 않고 한번의 묶음으로 처리하여
하나의 함수로 처리하는것을 볼수있다.
또다른 사용 예시로는 비교문에서 알수있다.
//튜플 비교문
(int a, byte b) left = (5, 10);
(long a, int b) right = (5, 10);
Console.WriteLine(left == right); // output: True
Console.WriteLine(left != right); // output: Falsevar t1 = (A: 5, B: 10);
var t2 = (B: 5, A: 10);
Console.WriteLine(t1 == t2); // output: True
Console.WriteLine(t1 != t2); // output: False
보이는것 처럼 두개의 묶음으로 비교하여 비교문을 줄일수 있다.
튜플은 Dictionary 에서도 사용이 가능하다.
var limitsLookup = new Dictionary<int, (int Min, int Max)>()
{
[2] = (4, 10),
[4] = (10, 20),
[6] = (0, 23)
};
if (limitsLookup.TryGetValue(4, out (int Min, int Max) limits))
{
Console.WriteLine($"Found limits: min is {limits.Min}, max is {limits.Max}");
}
// Output:// Found limits: min is 10, max is 20
이처럼 쉽게 저장하고 사용하는것을 볼수있다.
참고
1. 지금 사용한 튜플 형식사용은 기존 Tuple class 와는 다르다.
ㄴ 지금 사용한 형식은 System.ValueTuple 이고 Tuple class는 System.Tuple 이다.
Ref 키워드와 Out 키워드를 더 잘 이해하기 위해서는 call by refurence , call by value를 알고 보는 게 좋다.
Ref , Out키워드
정의부터 설명하자면
RefPass by Reference
ㄴ 얕은 복사 매개변수 지정자
Out Output Parameters
ㄴ 출력용 매개변수 - 내부에서 값을 할당해주어야 한다.
사용 방법
ref 와 out 사용법
함수 선언 시
리턴 값함수명 (ref & out키워드매개변수 타입변수 이름 ) <-함수를 선언 또는 구현 시에도 매개변수 앞에 써줘야 한다.
함수 사용 시
함수명( ref & out 키워드변수 ) <- 사용할 때에도 매개변수 앞에다 ref 키워드를 써줘야 한다.
publicvoidFuncRefB(ref int A){
A++;
}
publicvoidFunc( int A){
A++;
}
publicvoidFuncOutB(out int A){
A = 10; // 내부에서 값을 대입 하지 않으면 오류가 나온다.
}
...
{
int A;
FuncOutB(out A);
Console.WriteLine(A); // 내부에서 생성해서 받는다 Call by Refurence + @ 10Func(A);
Console.WriteLine(A); // 늘어나지 않는다 Call by Value 10FuncRefB(ref A);
Console.WriteLine(A); // 값이 늘어난다. Call by Refurence 11
}
이처럼 c나 c++처럼 포인터 참조형처럼 Call by Reference 형식으로 넘겨줄 수 있다.
(참고할 점)
1. Ref 키워드는 할당이 되어있어야 한다.
2. Out 은 Ref처럼 할당이 되어있지 않아도 사용 가능하지만. 내부에서 새로 할당한다.(이전 값은 사라짐)
3. Ref int -> int 오버로드는 가능하나 Out -> Ref , in 오버로드는 불가능하다.
구조체 같은 경우 기본적으로 call by value 형식이기 때문에 구조체를 ref 키워드로 넘겨주면 얕은 복사(주소 값)처럼 사용할 수 있다.
in 키워드
in : 읽기 전용 매개변수 지정자
함수 선언 시
리턴 값함수명( in 키워드매개변수 타입 변수이름) <-함수를 선언 또는 구현 시에도 매개변수 앞에 써줘야 한다.
함수 사용 시
함수명( 키워드변수 ) <- in은 사용할 때 앞에 붙여 주지 않는다.
voidFuncIn(inint num)
{
//num++; 내부 수정불가능
}
내부에서 수정이 불가능하기 때문에 혹여나 다른 값을 입력하거나 수정하는 실수를 미연에 방지할 수 있다.
Ref 와 in 키워드는 복사 비용을 참조로 변경하여 성능 향상을 생각할수 있다.
--추가--
out 키워드 의경우 C#7.0 버전부터는 튜블 반환을 지원했다.
튜플 반환이 있기전에 여러값을 반환 할수 없었기 때문에 out을 주로 사용하였다.
(int sum, int product) Calculate(int a, int b) => (a + b, a * b);
voidCalculate(int a, int b, outint sum, outint product)
{
sum = a + b;
product = a * b;
}
Calculate(2, 3, outint sum, outint product);
out 키워드는 성능이 중요한 코드나 오래된 api, 호환성 때문에 쓰인다.
반복적으로 많이 쓰일때 생성되는것보다 out으로 불필요한 메모리할당과 GC부하를 줄일수있다.